内 容
- 文字型と文字コード
- 文字列
- 文字列とポインタ
- 文字列配列とポインタ
- 文字列を扱う標準関数
文字型と文字コード
文字型
C言語で整数を扱うための主な型には、下表で示すようにchar型やint型などがあります。この中で、char型は通常、文字を表現するための型として利用されます。char型のサイズは1Byte(8bit)あり、半角の英数字や文字、記号などの1Byteのデータ幅で表現できる1バイト文字を表現することができます。
主な整数型の型とそのサイズ
| 宣言 | サイズ | 表現範囲 | |
|---|
| char | 1 | -128 〜 127 |  |
| short int | 2 | -32768 〜 32767 |  |
| int | 4 | -2147483648 〜 2147483647 |  |
| long int | 4 | -2147483648 〜 2147483647 | |
※1 サイズはchar型を1としたもので、その大きさは実行環境によって異なる。
※2 表現範囲も実行環境によって異なる。
※3 上記とは別に最上位ビットを符号として扱わないunsigned型を宣言できる
sizeof演算子
sizeof演算子は型の大きさを調べることのできる演算子です。このsizeof演算子とライブラリlimits.hで定義されている各型の最大値と最小値の定数を使って、あなたの実行環境における各型の扱える値の範囲とデータサイズを調べてみましょう。
sizeof_type.c
#include <stdio.h>
#include <limits.h>
int main(void)
{
printf("型 : min -- max(size)\n");
printf("----------:---------------------------\n");
printf("char : %d -- %d(%u)\n",CHAR_MIN,CHAR_MAX,(unsigned)sizeof(char));
printf("short int : %d -- %d(%u)\n",SHRT_MIN,SHRT_MAX,(unsigned)sizeof(short));
printf("int : %d -- %d(%u)\n",INT_MIN,INT_MAX,(unsigned)sizeof(int));
printf("long int : %ld -- %ld(%u)\n",LONG_MIN,LONG_MAX,(unsigned)sizeof(long));
return 0;
}
文字コード
コンピュータの内部で扱えるのは2進数だけでした。文字を扱うことはできません。そこで、文字を0と1からなる2進コードで置き換えてコンピュータで扱えるようにしました。これを文字コードと言います。下表に示したASCIIコードは、1963年にアメリカで生まれた標準規格です。一つの文字を7桁のコードで表しています。しかし、1バイト(8bit)を基本的な単位とするコンピュータでは、都合が悪いためASCIIコードをベースとして8ビットに拡張されたコードが利用されます。日本独自の規格としてJISコード(JIS X 0201)があります。
数字とアルファベットのASCIIコード表
| 数字 | 16進数 | | 小文字 | 16進数 | 大文字 | 16進数 | | 小文字 | 16進数 | 大文字 | 16進数 |
|---|
| 0 | 30 | | a | 61 | A | 41 | | n | 6E | N | 4E |
| 1 | 31 | | b | 62 | B | 42 | | o | 6F | O | 4F |
| 2 | 32 | | c | 63 | C | 43 | | p | 70 | P | 50 |
| 3 | 33 | | d | 64 | D | 44 | | q | 71 | Q | 51 |
| 4 | 34 | | e | 65 | E | 45 | | r | 72 | R | 52 |
| 5 | 35 | | f | 66 | F | 46 | | s | 73 | S | 53 |
| 6 | 36 | | g | 67 | G | 47 | | t | 74 | T | 54 |
| 7 | 37 | | h | 6 | H | 48 | | u | 75 | U | 55 |
| 8 | 38 | | i | 69 | I | 49 | | v | 76 | V | 56 |
| 9 | 39 | | j | 6A | J | 4A | | w | 77 | W | 57 |
| | | k | 6B | K | 4B | | x | 78 | X | 58 |
| | | l | 6C | L | 4C | | y | 79 | Y | 59 |
| | | m | 6D | M | 4D | | z | 7A | Z | 5A |
次のプログラムは文字とそのASCIIコードを16進数で表示する例です。
char_code.c
#include <stdio.h>
int main(void)
{
char ch;
ch = 'A'; //文字’A’を代入する
printf("%c(%#x)\n",ch,ch); //文字と16進数で表示する
ch = 0x41; //16進数を代入する
printf("%c(%#x)\n",ch,ch); //文字と16進数で表示する
return 0;
}
※ 変換指定子
%#x は16進数表記において先頭部分に、
0xを付け加えて表示する。
次のプログラムは文字一覧とそのASCIIコードを表示する例です。文字はコンピュータ内部ではコード(数値)として表現されていることを利用して、その値を1ずつ増加させることで全ての文字の一覧の表示を実現しています。
ascii_code.c
#include <stdio.h>
int main(void)
{
int i;
for(i=0; i<16; i++){
printf("%c(%x) ",0x20+i,0x20+i);
printf("%c(%x) ",0x30+i,0x30+i);
printf("%c(%x) ",0x40+i,0x40+i);
printf("%c(%x) ",0x50+i,0x50+i);
printf("%c(%x) ",0x60+i,0x60+i);
printf("%c(%x)\n",0x70+i,0x70+i);
}
return 0;
}
文字列
C言語には文字列を直接扱うことのできる型はありません。char型の配列を用意し、その各要素に一文字ずつを格納することで文字列を表現します。例えば、要素数6個からなる文字配列sを用意し、文字列"music"を扱いたければ、
char s[6];
s[0] = 'm';
s[1] = 'u';
s[2] = 's';
s[3] = 'i';
s[4] = 'c';
s[5] = '¥0'; //文字列の最後を示すナル文字
と記述することができます。このとき、ナル文字と呼ばれる特殊な文字
'¥0'(もしくは'\n')を最後に付け加えることで、文字列の最後を示すようにします。
また、初期化の場合に限れば、下記のように記述することもできます。
char s[6] = {'m', 'u', 's', 'i', 'c', '¥0'};
次のように文字列リテラルで初期化することもできます。(文字列を直接記述したものを文字列リテラルといいます。)この場合、明示的には記述されませんが、文字列の最後にナル文字
'¥0'が含まれています。
char s[6] = "music";
さらに、要素数を省略して書くこともできます。
char s[] = "music";
いずれにせよ、文字列"music"は下記の図のように文字配列に格納されることになります。
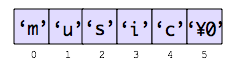
文字列の最後には、ナル文字¥0が含まれる
文字列を一文字ずつ表示する
print_str1.c
#include <stdio.h>
int main(void)
{
char s[6] = {'m', 'u', 's', 'i', 'c', '¥0'};
int i=0;
while(s[i] != '¥0'){ //ナル文字が現れるまで繰り返す
printf("%c", s[i]);
i++;
}
printf("¥n");
return 0;
}
文字列を表示する
文字配列を文字列"music"で初期化して、それを変換指定%sを使って表示する例です。変換指定%sは、ナル文字までの文字列を表示してくれます。
print_str2.c
#include <stdio.h>
int main(void)
{
char s[6] = "music"; //文字列の最後にはナル文字がある
printf("%s¥n", s); //文字列を表示する。
return 0;
}
文字列を格納する配列の要素数は、ナル文字¥0の分を+1する。
文字列の変換指定は、%s
変換指定%sはナル文字までを表示する。
変換指定%sは文字配列にナル文字が登場するまでの文字を表示します。文字列の途中にナル文字を代入する例を見てみましょう。
print_str3.c
#include <stdio.h>
int main(void)
{
char s[6] = "music"; //文字列の最後にはNULL文字がある
s[3] = '¥0'; //途中にナル文字を代入
printf("%s¥n", s); //"mus"までが表示される。
return 0;
}
空白文字を含む文字列の入力
空白文字を含む文字列をscanfを使って読み込むと、空白文字を文字列の終端と見なすため最後まで読み込むことができません。そこで、一文字を読み込む関数getcharを使います。このgetcharを繰り返し呼び出すことで、空白文字を含む文字列を読み込むようにします。次の例では、改行コード'\n'が入力されたところで読み込みを終了するようにしています。ただし、そのままでは文字列の最後を示すNULL文字'\0'がないので、NULL文字を追加する処理が必要になります。
getchar.c
#include <stdio.h>
int main(void)
{
int i = 0;
char ch;
char str[32];
printf("文字列>> ");
while((ch = getchar()) != '\n') str[i++]=ch;
str[i] = '\0'; //NULL文字の追加
printf("%s\n", str);
return 0;
}
文字列とポインタ
ポインタで文字列を表示する
次のプログラムは文字列をポインタを使って画面に表示する例です。char型へのポインタstrは、文字リテラル"Apple"を指し示すように初期化されています。これは、メモリの定数領域に文字列リテラル"Apple"を格納し、その先頭アドレスがポインタstrに代入されることを意味します。関数printfにポインタstr、すなわち文字列リテラル"Apple"が格納されているメモリの先頭アドレスが渡されることで、"Apple"と画面に表示しています。
例 pstring.c
#include <stdio.h>
int main(void)
{
char *str ="Apple";
printf("%s",str);
return 0;
}
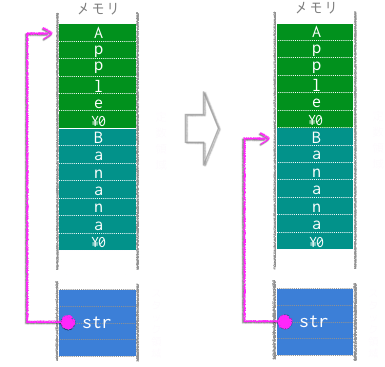
次のプログラムでは、ある文字列を指し示していたポインタが別の文字列を指し示すように変更されています。文字列リテラル"Apple"も"Banana"もメモリの定数領域に格納されています。最初に文字リテラル"Apple"を指し示していたポインタstrですが、その後、"Banana"を代入することで文字列リテラル"Banana"の先頭アドレスで書き換えられます。
例 pstring.c
#include <stdio.h>
int main(void)
{
char *str ="Apple";
printf("%s",str);
str = "Banana"; //"Banana"の先頭アドレスを代入
printf("%s",str);
return 0;
}
ポインタで文字列を操作する
次のプログラムは、ポインタを使って文字列を1文字ずつ表示する例です。関数print_string(char *s)は文字列sの先頭アドレスを引数で受け取り、その文字列のNULL文字が現れるまで先頭から順に文字を表示するように定義しています。
例 printstring.c
#include <stdio.h>
void print_string(char *s);
int main(void)
{
char str[] ="Apple";
print_string(str);
return 0;
}
void print_string(char *s)
{
while(*s != '\0'){ //NULL文字が現れるまで繰り返す
putchar(*s++);
}
}
次に、文字列をコピーする関数を作ってみます。関数str_copyは2つのchar型ポインタを引数とします。一つ目の引数datがコピー先の文字列を、二つ目の引数srcがコピー元の文字列を表します。while文では'\0'に到達するまで一文字ずつコピーしますが、NULL文字'\0'がコピーされないので、その後でNULL文字のコピーをしていることに注意しましょう。
例 str_copy.c
#include <stdio.h>
char* str_copy(char *dat, char *src);
int main(void)
{
char str1[8] ="Apple";
char str2[8];
printf("%s\n",str_copy(str2,str1));
return 0;
}
char* str_copy(char *dat, char *src)
{
char *p = dat;
while(*src != '\0') *dat++ = *src++;
*dat = *str; //NULL文字のコピー
return p;
}
文字列配列とポインタ
文字列配列と2次元配列
文字列は文字の集まりである1次元配列で扱われます。複数の文字列をまとめて扱いたい場合には文字列の配列、すなわち文字の2次元配列として扱うことができます。以下に、3つの文字列を文字列配列(文字の2次元配列)で扱った例を示します。
例 str_array.c
#include <stdio.h>
int main(void)
{
char str[3][6] = {"One", "Two", "Three"}; //文字列配列の初期化
int i;
for(i=0; i<3; i++)
printf("%s\n", str[i]); //各文字列の先頭アドレスstr[i]
return 0;
}
ポインタを使って文字列配列を操作する
文字列配列をポインタを使って扱ってみます。それぞれの文字列を指し示すためには文字列分のポインタが必要になります。文字列ごとにポインタを用意することもできますが、ポインタを要素とするポインタ配列を用意すれば、同じ名前でまとめて扱うことができるようになります。次のプログラムの関数print_stringではポインタの配列とその個数を引数として受け取り、複数の文字列をまとめて表示しています。
例 str_array.c
#include <stdio.h>
void print_string(char *p[], int num);
int main(void)
{
char *strp[3] = {"One","Two","Three"};
print_string(strp,3);
return 0;
}
void print_string(char *p[], int num)
{
int i;
for(i=0; i<num; i++){
printf("%s\n",*(dp+i));
}
}
ダブルポインタ
ダブルポインタはポインタを指し示すポインタでした。別の言い方をすると、ポインタが格納されているメモリの先頭アドレスを格納するポインタです。
次のプログラムは、複数の文字列を指し示すポインタ配列の関数間での受け渡しを、ダブルポインタを使って実現した例です。ポインタ配列*strp[3]の配列名strpはポインタ配列の開始アドレスを指し示すポインタとして利用できます。ポインタ配列の各要素には文字列の格納先の先頭アドレスが格納されており、この先頭アドレスの格納先を示すポインタが配列名であるstrpということになります。すなわちstrpはポインタが格納されている場所を示すポインタと言えます。
例 double_pointer.c
#include <stdio.h>
void print_string(char **dp, int num);
int main(void)
{
char *strp[3] = {"One","Two","Three"};
print_string(strp,3); //ポインタ配列の開始アドレスを渡す
return 0;
}
void print_string(char **dp, int num) //ダブルポインタ
{
int i;
for(i=0; i<num; i++){
printf("%s\n",*(dp+i));
}
}
以下は、上記のプログラムにおいて、ポインタ配列をダブルポインタを使って関数間で共有していることを確認するために、ポインタ配列とダブルポインタのアドレスの表示を追加したプログラム例です。
double_pointer_address.c
#include <stdio.h>
void print_string(char **dp, int num);
int main(void)
{
char *strp[3] = {"One","Two","Three"};
int i;
printf("ポインタ配列strpの開始アドレス: %p\n",strp);
for(i=0; i<3; i++)
//ポインタ配列の要素の格納先アドレス、アドレス,アドレス
printf("&strp[%d] %p -> %p[ %s ]\n",i,&strp[i],strp[i],strp[i]);
print_string(strp,3);
return 0;
}
void print_string(char **dp, int num)
{
int i;
for(i=0; i<num; i++){
printf(" dp+%d: %p -> %p[ %s ]\n",i,dp+i,*(dp+i),*(dp+i));
}
}
文字列を扱う標準関数
C言語には文字列を扱うための標準ライブラリstring.hが、また数字からなる文字列を数値へ変換するための標準ライブラリstlib.hが用意されています。以下に各ライブラリで定義されている主な関数を示します。
文字列の長さを求める
| strlen |
|---|
| ヘッダ | string.h |
| 形式 | size_t strlen(const char *str) |
| 説明 | 引数strの文字列の長さ。null文字は含めない。 |
| 戻り値 | 引数strの文字列の長さ(文字数) |
文字列をコピーする
| strcpy |
|---|
| ヘッダ | string.h |
| 形式 | char *strcpy(char *s1, const char *s2) |
| 説明 | 引数s2が示す文字列を、引数s1が示す配列へコピーする。 |
| 戻り値 | 引数s1の値 |
| strncpy |
|---|
| ヘッダ | string.h |
| 形式 | char *strncpy(char *s1, const char *s2, size_t n) |
| 説明 | 引数s2が示す文字列を、引数s1が示す配列へコピーする。ただし、コピーする最大文字数はnまでとする。s2が示す文字列の長さがn以上の場合は以降をnull文字で埋め尽くす。 |
| 戻り値 | 引数s1の値 |
文字列を連結する
| strcat |
|---|
| ヘッダ | string.h |
| 形式 | char *strcat(char *s1, const char *s2) |
| 説明 | 引数s1が示す文字列の後に、引数s2が示す文字列を連結する。。 |
| 戻り値 | 引数s1の値 |
| strncat |
|---|
| ヘッダ | string.h |
| 形式 | char *strncat(char *s1, const char *s2, size_t n) |
| 説明 | 引数s1が示す文字列の後に、引数s2が示す文字列を連結する。ただし、連結可能な引数s2が示す文字列の最大文字数はnまでとする。 |
| 戻り値 | 引数s1の値 |
文字列の大小関係
| strcmp |
|---|
| ヘッダ | string.h |
| 形式 | size_t strcmp(const char *s1, const char *s2) |
| 説明 | 引数s1が示す文字列と引数s2が示す文字列の大小関係(辞書的順序)を調べる。 |
| 戻り値 | 等しいときには 0 を, s1の方が大き時には正の整数を、s1 の方が小さいときには負の値を返す。 |
| strncmp |
|---|
| ヘッダ | string.h |
| 形式 | size_t strncmp(const char *s, const char s2, size_t n) |
| 説明 | 引数s1が示す文字列と引数s2が示す文字列の先頭からn文字目までの大小関係(辞書的順序)を調べる。 |
| 戻り値 | 等しいときには 0 を, s1の方が大き時には正の整数を、s1 の方が小さいときには負の値を返す。 |
文字列・数値変換
| atoi |
|---|
| ヘッダ | stlib.h |
| 形式 | int ato(const char *str) |
| 説明 | 引数strが示す文字列を、int型の値に変換する。 |
| 戻り値 | 変換された値 |
| atol |
|---|
| ヘッダ | stlib.h |
| 形式 | long atol(const char *str) |
| 説明 | 引数strが示す文字列を、long型の値に変換する。 |
| 戻り値 | 変換された値 |
| atof |
|---|
| ヘッダ | stlib.h |
| 形式 | double atof(const char *str) |
| 説明 | 引数strが示す文字列を、double型の値に変換する。 |
| 戻り値 | 変換された値 |
標準ライブラリを利用したプログラム例
stdfuncs.c
#include <stdio.h>
#include <string.h>
int main(void)
{
char str1[12] = "Peach";
char str2[12] = "Beach";
char str3[12];
printf("str1=%s str2=%s\n",str1,str2);
printf("[strlen] str1の文字数は、%lu個です。\n",strlen(str1)); //文字数
if(strcmp(str1,str2)) //比較
printf("[strcmp] str1とstr2は異なる文字列です。\n");
else
printf("[strcmp] str1とstr2は同じ文字列です。\n");
strcpy(str3,str1); //copy
printf("[strcpy] copy str3 from str1\"%s\"\n",str3);
strcat(str1,str2); //連結
printf("[strcat] str1 + str2 -> %s\n",str1);
return 0;
}
expand_lessBack to TOP